
Bayesian Optimization: Maximizing Efficiency in Hyperparameter Tuning
Unlocking the Black Box: Navigating Hyperparameter Space with Bayesian Optimization

The Challenge
Hyperparameter tuning is a crucial step in the machine learning model development process. It involves finding the optimal set of hyperparameters for a given model to maximize its performance. These hyperparameters, such as learning rates, regularization strengths, and network architectures, significantly impact a model's accuracy and generalization ability.
The challenge lies in exploring this high-dimensional space efficiently. Traditional methods, like grid search or random search, are brute-force approaches that can be computationally expensive and time-consuming, especially when dealing with complex models and large datasets.
Bayesian Optimization
Bayesian Optimization is an intelligent and efficient alternative to traditional hyperparameter tuning methods. At its core, it combines probabilistic models with optimization to guide the search for optimal hyperparameters, making it a powerful tool for automating this process.
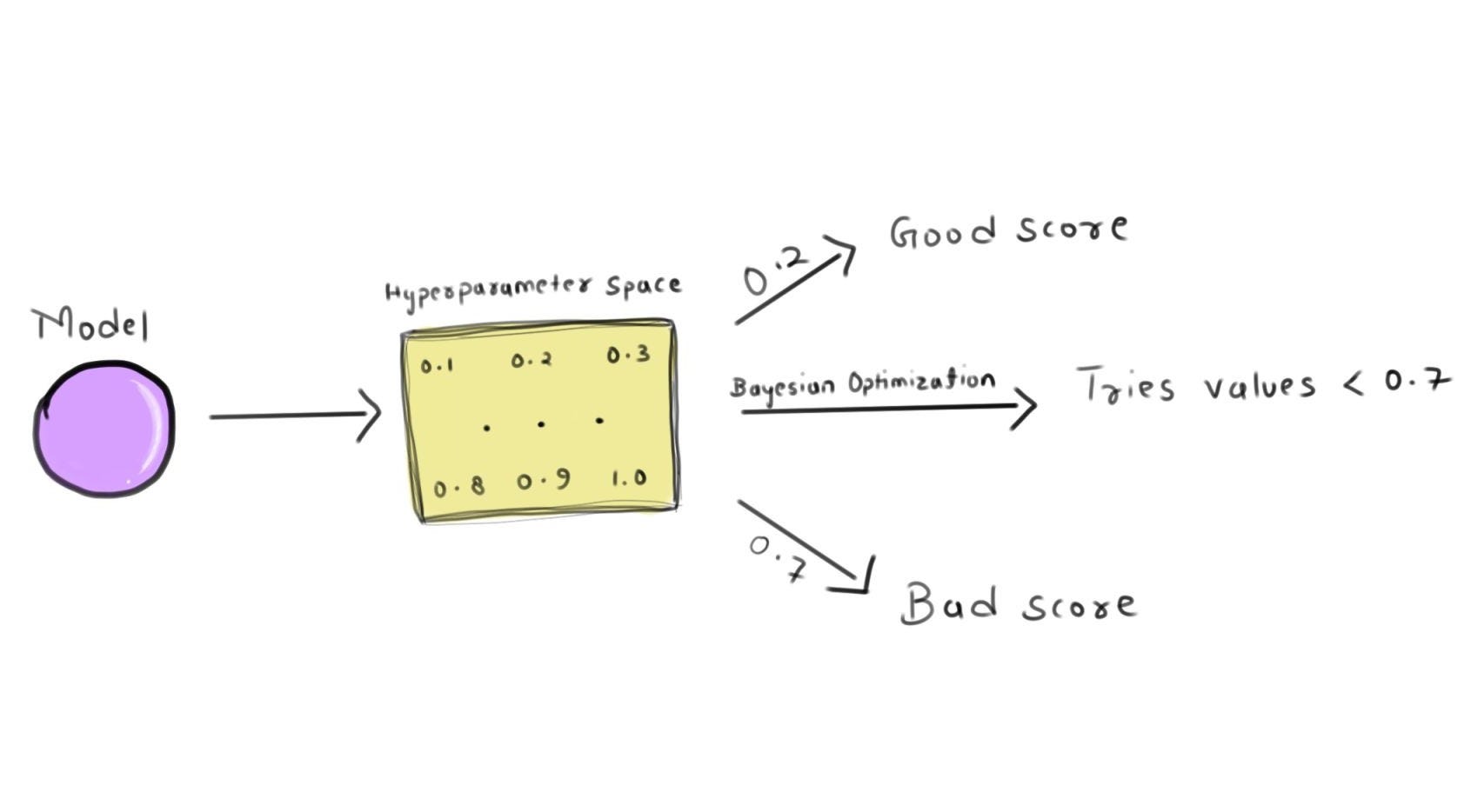
The underlying principle
At the heart of Bayesian Optimization is the idea of modeling the objective function (the performance metric you want to maximize or minimize) as a probabilistic surrogate. This surrogate function estimates the true objective function, allowing us to make informed decisions about where to explore the hyperparameter space next.
The algorithm starts by creating a probabilistic model (typically a Gaussian Process) based on the initial evaluations of the objective function. This model provides not only predictions of the objective function but also uncertainty estimates for each prediction.
Key components
Gaussian Process (GP): The GP is a flexible and powerful tool for modeling the unknown objective function. It assumes that the function values at different points are jointly Gaussian-distributed. The mean and covariance functions of the GP are updated as new data points are evaluated.
Acquisition Function: This is a key concept in Bayesian Optimization. The acquisition function guides the search by balancing exploration (sampling uncertain regions) and exploitation (sampling regions with high predicted performance). Common acquisition functions include Probability of Improvement (PI), Expected Improvement (EI), and Upper Confidence Bound (UCB).
Bayesian Update Rule: After obtaining new data points, the GP model is updated using the Bayesian update rule. This process iteratively refines the surrogate model, focusing the search on promising regions of the hyperparameter space.
A simple example
Consider the task of optimizing the learning rate, denoted as η, for a neural network. The objective function f(η) is the accuracy of the model on a validation set.
Gaussian Process Model:
The Gaussian Process (GP) models the objective function as a distribution over functions. The mean m(η) and covariance k(η,η′) functions characterize this distribution:
m(η) = mean(η)
k(η,η′) = covariance(η,η′)
As new data points are collected, the GP is updated using the Bayesian update rule:
Acquisition Function:
The acquisition function guides the exploration-exploitation trade-off. Let's consider the Expected Improvement (EI) as the acquisition function:
EI(η) = E[max(0, f(current best) − f(η))]
The optimization process involves maximizing this acquisition function to determine the next hyperparameter configuration.
Iterative Process:
Initialization: Randomly sample a few learning rates and evaluate their accuracies.
Gaussian Process Modeling: Build the GP model based on the initial evaluations.
Acquisition Function Optimization: Maximize the acquisition function to select the next learning rate to evaluate.
Evaluate Objective Function: Obtain the accuracy for the selected learning rate.
Update Gaussian Process: Update the GP model with the new data point.
Repeat: Iterate these steps until convergence or a predefined number of iterations.
Conclusion
With Bayesian Optimization, finding the optimal settings for your model becomes a guided journey rather than a blind search. It's like having a knowledgeable companion by your side, helping you make better decisions in the complex world of hyperparameter tuning.
Thank you for reading,
Stay happy and be kind ❤️